

This is a follow-up to This Post on self-reported IQ among readers of the blog slatestarcodex, which means it's almost completely meaningless unless you first read that post.
I'll reiterate the main point I was intending to make:
The point I want to make is that claiming that some subset of the population is two and a half standard deviations above the mean is a more extreme claim than it initially might sound like (this goes for other traits and contexts as well). It’s easy to think something along the lines of “I bet mostly high-IQ people are attracted to the blog”, and assume that that is enough to shift the mean to whatever you consider to be high-IQ. That thought process is basically a version of the base-rate fallacy.
The response to my post was pretty much exactly what I hoped. I worried people would find it completely trivial and just comment something like "whatever, no one takes self-reports of IQ seriously anyway". Instead I got several comments telling me I'm wrong and forcing me to think about the problem more carefully. Fun!
Thanks for all the comments! But I still don't think Slate Star Codex readers have an IQ of 137. Here I'll respond to some of the themes that came up.
EDIT: Two additional arguments I found interesting came up came up in response to this post. Fat-tails and selection bias on who knows their IQ. I’m adding a response to them as a foot-note.1
Assumptions + data
My probability of interest toy model was a way to test my intuition about frequencies/base-rates on the normal distribution (link to browser app). But for the conclusion that a mean of 137 IQ is probably over-reporting we also have other, more circumstantial, sources of information. We know the data is self-report that have clear self-reporty artefacts and we know that people tend to overreport/overestimate these kinds of things (flattering traits).
One reader pointed out that the SAT-scores in the dataset were also very high. I suspect more people have taken the SAT than have taken a valid IQ-test so I would trust those scores a bit more. Still the same psychological processes that would make someone overreport IQ would plausibly make someone overreport their SAT, at least a bit. The SAT average did not turn out as extreme when removing non-valid responses according to this reader2. I redid the analysis and when removing scores that are impossible on the more recent SAT versions the mean ended up at around 1.9 standard deviations above the mean. (I'm basing that number on percentiles which vary a bit depending on which year they took the test.)
I’ll count this data-point in favour of my position (1.9 is less than 2.5 after all), however the core of my post was about constructing a guess/prior beforehand and pointing out that 2.5 SD is a more extreme claim than it sounds like3, so I think it's reasonable that people mainly focused on questioning how I set up my assumptions there. I’ll move on to those objections now.
The probability of interest shouldn't max out at 1!
One person pointed out that it's weird to expect the "probability of interest" to max out at 100%. Even if likelihood of finding the the blog interesting is related to IQ, it should be related to other stuff too, so it would get “satiated” at some lower value. However, since I'm only interested in the average here, not in how large the resulting subpopulation ends up being, only the shape of the interest function is relevant. If we keep the same shape but flatten it so that every point of the curve get's half as high (0.5 becomes 0.25 etc) that wouldn't affect the average. Illustrated in the two pictures bellow:


There's nothing implausible about that “extreme” final interest-function!
Some readers commented that they didn't find anything implausible about the final interest-function (the function that that was needed in order to shift the mean to 137 IQ). I expected people to have different intuitions about this, which is why I made the web-app.
Several readers commented that they don't think it's unlikely that an average IQ person would have an almost 0 percent chance of being in SSC. I don’t agree, but more importantly: it's not enough for the probability of interest to be low at the mean. It has to be very low far above the mean too!
Copying from a comment I wrote on reddit:
To argue the case against the final interest function in the context of slatestarcodex readers, if you look at "probability of interest" for 130 IQ you have 0.002%, for 145 you have 3%, with the function flattening out/starting to get saturated at quite absurd levels.
Another example from that final interest function is if we look at relative rates of probability of interest (to get around the problem of the function saturating at levels that are unmeasurable):
-A person with 145 IQ is then supposed to be 1767 times as likely to find the blog interesting compared to someone with average IQ.
-Someone with 160 IQ should be 1413 times as likely to find the blog interesting as someone with 115 IQ."
I simply do not find this plausible.
Closely related to this some readers also disagreed that the interest function should satiate/pan out at all. Instead they argued there's even more wisdom and depth to be found on slatestarcodex for someone who's even smarter, going on and on and on.
I do not share this intuition either. There's plenty of stimulating things to read online (and offline). One could argue that someone who is a super-genius has more open doors when it comes to what to read and do - more things that compete for their appetite for reading. As I brought up in the post, Scott Alexander usually makes his points very clearly. That doesn’t preclude there being additional depth to be found beyond that clarity, but I don’t think that additional depth would make someone thousands of times more likely to find it interesting as someone who’s fully capable of understanding the central point of a given post.4
And to be clear, the exponential rise in probability of interest, continuing indefinitely, would have to be similarly extreme to the final interest function to work. The relative rates would turn out similar.5
Probability of interest is too simplified!
As I wrote in the original post:
Even if we grant that “probability of interest” is a clearly simplified way of thinking about this, I don’t think a more complicated conceptualization of the function would justify something like the final graph. For example: Maybe you think high IQ-people are also more likely to come across the blog in the first place, and/or are more likely to actually respond to the yearly reader survey. I don’t think that would be enough.
Many made this point: I'm mixing in too much base-rates here. Well I don't think you can get away from base-rates that easily (or at all, ever). I chose to talk about probability of interest because it was one step easier to think about, but for the sake of argument, let's instead imagine two logistic functions. First people have to come across the blog, then people need to find it interesting. Let's say coming across the blog is related to IQ too. So if you have a 0.4 probability of coming across the blog and a 0.4 probability of finding it interesting you have a 0.4 x 0.4 = 0.16 probability of becoming a reader. For simplicity's sake let's say the interest function has the same shape as the finding function. I could take the interest function I found somewhat plausible and multiply it by itself, but this doesn't really do that much:

Low probabilities can get miniscule, but when the function plane out, which I still think is a reasonable assumption, the higher probabilities only shrink a bit. As I pointed out earlier, for the needed function probabilities are low even two and three standard deviations above the mean. Still it's a fair point that realistically readers aren't uncorrelated (as the user Badspeler and others pointed out).
Relatedly: Social networks
This was one of the more interesting counterarguments that came up - that who comes across the blog is related to close-knit communities. The user Malmesbury comments:
A lot of ACX readers are coming from the Lesswrong/Rat-sphere and this community probably has a much steeper interest function, since it can get really technical there. That might drive the IQ scores of Scott's readers up.
Indeed, maybe one could argue that people found slatestarcodex only after reading more obscure, less accessible writing on lesswrong. Interestingly the survey contained information about how people were referred to the blog:

People coming from LessWrong itself is turns out to around 19%, though some of the other categories could maybe partially relate to some vague rationalist-sphere.
Furthermore, social networks usually have a graph-theoretical property called “small-worldness”. This is the thing that lies behind the “six degrees of separation” idea. As far as I’ve understood this counter-intuitive phenomenon is simply a consequence of the fact that just a moderate degree of randomness in a how a network is organized greatly decreases the average shortest path between nodes. In some sense small-worldness is simply a likely property for a network to have. (Veratasium has a fun video about this).

(Recreated using code from Dai Shizuka)
I think this sort of thing would quickly break whatever social clustering would gate-keep the visibility of this public blog. For example, I once shared The Toxoplasma Of Rage with my all of my facebook friends- This phenomenon implies that the probability-of-coming-across-the-blog function wouldn’t become very extreme.
At the end of the day you can’t get away from base-rates.
The part in which I call people out for being interested in a post I myself wrote and shared
I want to be clear that I don’t intend these posts as some sort of “attack” on the readership of slatestarcodex. I read and enjoyed the blog regularly for years, and still occasionally read and enjoy the new
. It may seem like I have an axe to grind with the rationalists given what my blog has ended up focusing on so far, but it all comes from a place of love.6 Even though the post could have been interpreted as some sort of attack, not a single person has been rude to me about it. I see their engaged disagreements with my arguments only as kindness.Still, I want to make one final point: I get the feeling that a lot of people want the IQ of slatestarcodex readers to be 137. I assume this is because of identification with the group, and it's not weird to want to defend your tribe. From the perspective of Scott Alexander, who wrote the blog, I insist that good accessible writing is a compliment. I get why one would take a the fact that ones blog attracts intelligent people as a compliment too, but if I wrote something that only geniuses could understand I would take that less as evidence that I myself am a genius and more as evidence that my writing in unnecessarily obscure.
But for anyone who isn't Scott it's only natural that thinking you belong to a group of smart people feels good. I recently heard rumors that the certified genius mathematician Terry Tao was once dangerously addicted to the same game I've been dangerously addicted to (Civilization) and felt a silly sense of pride. On the other hand I don't think thinking like this actually makes sense. Your level of some trait isn't actually determined by the average of some group you belong to. If you're 170cm and from the Netherlands, it doesn't matter that Dutch people on average are freakishly tall. If someone came out with an argument that the methodology of the height-survey was flawed, resulting in overreporting, that wouldn't make you shorter! (For something less measurable or unknown trying to guess at your level based on group-belongings can sometimes make sense, but there has to be better proxies than what blog you read.)
Much more importantly, your IQ does not determine your worth or dignity as a human being! I don't know my IQ, but I'm pretty sure it's something completely unremarkable. Does that mean I'm a worthless sack of crap? No! I'm a kind friend, a friendly co-worker, a hard-working dad and I'm usually not too rude online. I'm Swedish and complimenting ourselves is sort of one of our deadly sins so it's very embarrassing to say all this but honestly: I'm pretty OK! A more powerful cognitive machinery wouldn't make me more deserving.
Growth mindset research has gotten a lot of valid criticism the last decade. Especially the intervention studies seem too good to be true in exactly the way pre-replication crisis psychology often did. But one part of that literature that I still believe in is that constantly viewing your performances as evidence of your innate ability leads to anxiety. I used to think a lot like that when I was younger. Whenever I found something too hard to understand I'd spiral away, catastrophizing about whether I was secretly an idiot who would never be able to achieve anything in my pathetic excuse for a life. It was completely unnecessary and I'm happy to report I've (mostly) outgrown it.
Worst case scenario obsessing over intelligence almost becomes reminiscent of the psychology around body-anxiety in eating disorders. A constant habit of comparing oneself to others. A self-destructive over-valuation of what having a certain body/brain implies about your worth as a person. I really hope my first post didn't get engagement just because of those types of obsessions.
The smartest people I know don't seem obsessively interested in seeming smart or even being smart. Instead they're just interested in the things themselves. So don't worry about being dumb. Just be dumb, ask confused question, try to get smarter. Have fun with all that is interesting in this world.
I got several interesting comments on the subreddit to this follow-up post. I’m adding an edit with my thoughts on them here:
What if IQ is fat-tailed?
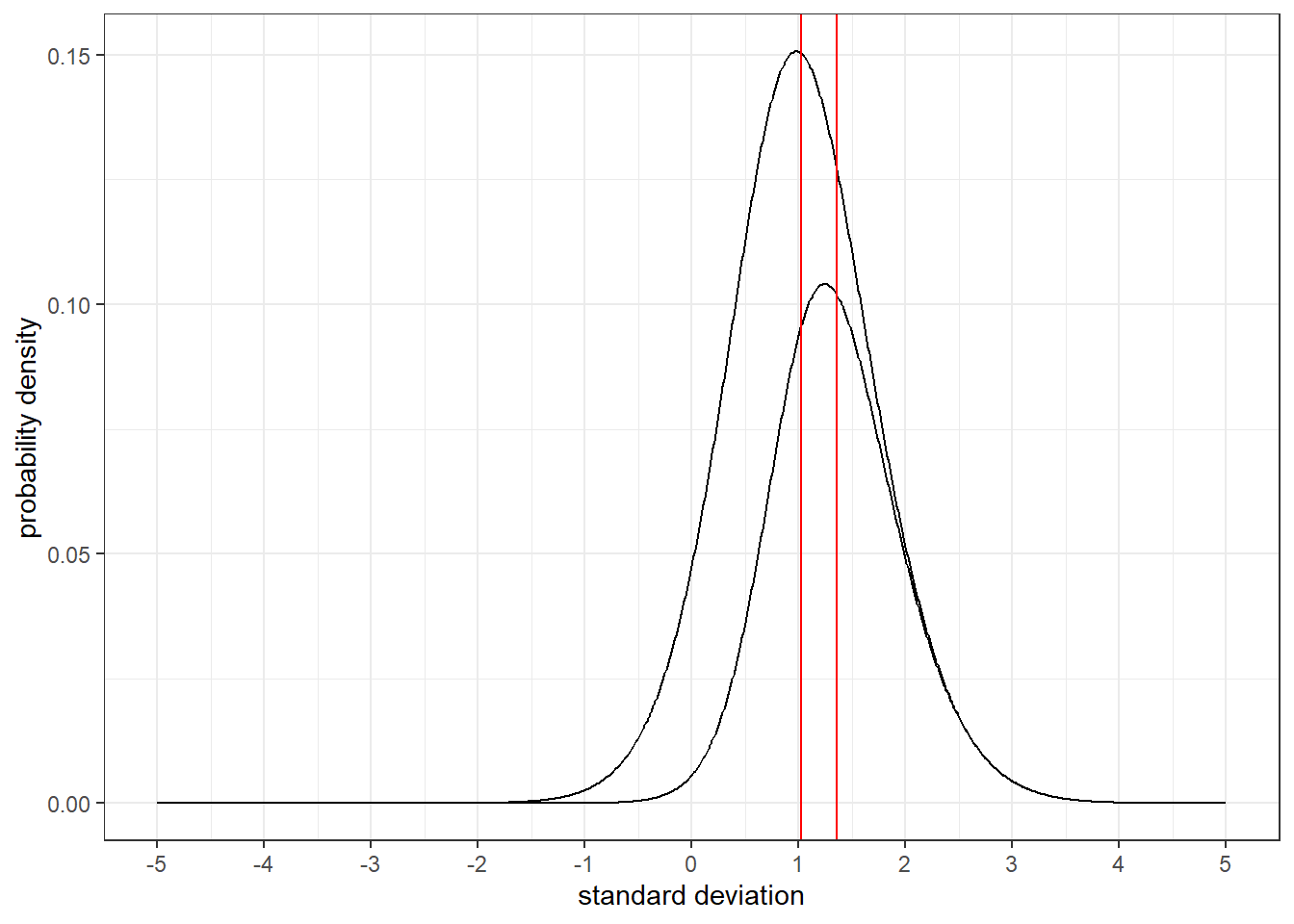
The reddit user u/emma_redd pointed out that IQ-scores may be less normally distributed than my model assumes. From what I’ve been taught well designed IQ tests are explicitly standardized to follow a normal distribution, still since there’s much fewer people at the tails even moderately large sample could fail to fit the tails properly (maybe). So how much would fatter tails affect things? It’s hard to know since fat tails could mean different things. One simple way to investigate it is to take a t-distribution with low degrees of freedom instead of a normal distribution. Bellow is a t-distribution with 5 degrees of freedom:

As you can see the tails are significantly fatter. What’s harder to see when it’s zoomed out is that the ratio increases the further out on the tails you get. 145 IQ is now 3.9 times as common as on the normal distribution, while 160 IQ is 38 times as common!
However, much like multiplying the interest function by itself this affects things less than you may expect:

The black line represents the mean obtained from a normal distribution while the red line represents the mean using the t-distribution. Even though extreme scores become more common on a fat-tailed distribution, they’re still likely to become rarer and rarer, and are still rare in absolute numbers. Still, the t-distribution is an idealized case and the actual distribution may be something more messy.
People who know their IQ scores may have higher IQ scores!
Many commenters pointed out that knowing your IQ may be conditioned on trying to get into mensa or being tested for a gifted-kids program when you were a child. If this is the case the subset of survey responders who know their IQ may have higher scores than those who leave the question blank.
This would be a different process from conscious or unconscious overreporting. In my first post I suspected there was some “dishonesty” or self-deception affecting things, but you could possibly get high scores from pure selection bias as well. I don’t know how likely this is because I have no idea how common those kinds of tests are in the U.S.
Many other possible filters were also pointed out, like maybe the readers who respond to the survey are more engaged subscribers that are not representative of the wider readership. To be clear, this would still mean that the survey average shouldn’t be taken at face value if you think of it as representative of who reads the blog. I think my main point that I reiterated at the start of this post still stands.
I'm not American so I don't know a lot about the SAT but from what I've read online it seems there was a previous version with even higher scores and readers haven't reported data about which version of the test they're reporting which might complicate things for a bit. Most of the data was in the spectrum of the current SAT so I assumed people reported that score and excluded anything above the maximum.
well, if you assume something is normally distributed at least.
I think the logistic function for interest I chose approximates this additional depth reasonably well since it never fully reaches 1.
At least if the IQ-distribution is bounded to existing levels of IQ. If we just talk about idealized math, an infinite sample and an infinite normal distribution, things might turn out different.
I’ve also found the subreddit to be one of the few places where you can have engaged online discussions about a variety of interesting topics without it quickly derailing into a shouting match. I may not share the political sensibilities with the majority of the people there, but that sort of environment is worth 1000 times any echo-chamber.
I have a trivial objection which is the best I can do with my IQ. 137 is not the self-reported IQ among readers of the blog slatestarcodex but the self-reported IQ among those who answered the IQ question in the survey. I've been reading that blog since march 2013 and never bothered to fill the survey. Low conscientiousness. It's very likely those who did answer the IQ question are a self selected group and differ from the general readership on various metrics including caring about IQ enough to take a decent test.
Re: how common is IQ testing in US schools~
From my experience, it was at least somewhat common in flyover states.
Between 4.5-7 years old I was in public schools in North Dakota, Michigan, Kansas, and Florida. In the 80’s each of these states had gifted programs in public schools, and each gave an IQ test to determine eligibility. I forget what the min age was by state for these programs, and can’t find that data for that time on the web. My rather mediocre public school in rural Florida gave me an IQ test a few months after I moved there, in second grade, and entered the gifted program. My mom told me later that the kindergarten teacher in Michigan had proposed testing me (thanks, Mr Panconi), but was rejected by the principal because the MI gifted program started at a later grade. My little sis (t-4y) was also in that goof-off gifted program. Between the two of us, it’s the only time we’ve taken a formally administered IQ test.
Current:
There is a gifted program in Texas public schools, with formally administered IQ tests given. We raised our daughter in Taiwan (white American ex-pats, zero East Asian genetics AFAIK), she didn’t start school in the US until 9th grade, so we said “don’t bother with going into gifted, it’s mostly a waste of time.” So her IQ hasn’t been measured, and if our lives are any pattern, pretty good chance that she won’t.
Second anecdote: my wife and I were both required to take the PSAT in Florida in 8th grade, around 1990. My daughter, now 16, was ‘invited’ to take the PSAT in 10th grade in Texas. That seems late to me. The SAT score that I got in 10th grade is the one I used for applying to college.
Re: “there’s a universe of deeper content available for people, it doesn’t seem like people with particularly high IQ would inordinately land on SSC/ACX.”
There is a huge amount of primary content, but most sucks. Scott is exceptionally good at putting thoughts together that include nuance that spans multiple and sometimes highly disparate sources. And this is extremely rare, IMO.
I read published research articles (and Arxiv preprints) across a science-centered but wide spectrum of domains on a weekly basis, for fun. Parsing most papers requires more effort than necessary, in no small part because of the formulaic structure that virtually always ends up going light on digging into the nuances of lines of reasoning or methods in citations, and the silly style of journal-ese that people publishing papers always seem to use. Conversely, about 15 years ago I mostly stopped reading Science, Nature, MIT Review and the other big-name journals and aggregators once they became overtly politicized. Finding very readable, adequately deep analysis of new science and became very difficult. There are more than a few similarly minded folks I know, who read SSC/ACX because it’s somewhat singular.